This is my small review of 8-bit cyrillic encodings universe. I didnʼt try to say anything for encodings not interesting for me (e.g. Tajik); if you didnʼt find enough information, go to links section. In this article, "encoding" is used as alias for more standard "character set". I hope this wonʼt be problem until next major rewriting.
As of 2016, this material gets more and more historic. There are some areas where 8-bit encodings are still in use (for example, I have a FidoNet point and keep reading and writing there), but majority has been already moved to Unicode. I appreciate this process.
All pictures shows top half (0x80-0xFF) only. Range 0x00-0x7F is equal to the same of us-ascii and iso-8859-1. Most pictures were got from Andrew Porokhnyak and Fingertipsoft, thanks to both:)
Encoding groups:
KOI8 group was the most widespread for the long time in traditional russian and ukrainian Internet due to historical reasons: it was used in first localizations of Unix systems. KOI stands for Russian abbreviation of "Information exchange code". Current group consists at least of:
KOI group falls into KOI8 group and KOI7 group (now historic). KOI7 encodings were used on RSX-11, RT-11 and similar systems. All KOI8 encodings have identical contents of codes 0x00-0x7F (the same as in US-ASCII) and 0xC0-0xFF (32 russian letters, i.e. full alphabet without Io/io, in both cases). Order of russian letters isnʼt alphabetical, but bound to order of latin alphabet letters with the same of similar pronounciation. Unrelated letters are bound in almost arbitrary way (Ю(Yu) - @, Я(Ya) - Q, Э(E) - \). Also, big letters are placed after small ones; this is compatibility issue with KOI7 encodings. In original KOI8, contents of 0x80-0xBF is absent at all (for 8-bit meaning) or identical to 0x00-0x3F (for 7-bit meaning). Different encodings in KOI8 group defines contents of 0x80-0xBF area in very different way.
KOI group originates from Soviet standard GOST 19768-74, which defined three KOI7 variants and one KOI8. Donʼt mix this with GOST 19768-87, which defines completely another encodings (see later for ISO-8859-5 and ALT group).
Some words for encodings unlisted here. DIS-8859-5 is generally known as another name for KOI8-R, but I suppose it had defined only standard letter group and Io/io. A KOI8-C is known to me as rarely seen mix of KOI8 in 0xC0-0xFF and CP1251 in 0x80-0xBF; I didnʼt see any standard for it. There is another KOI8-C which had added letters for old (before 1918) Russian alphabet, and also for most Slavonic alphabets based on Cyrillics; use Google for details. KOI8-RUB is yet another invention to support Ukrainian and Belorussian letters, not popular now. This list isnʼt complete...
The following encodings: KOI8-K1, KOI8-L2, KOI8-CS2 are not Cyrillic; they was created for Czech and Slovak languages. Common name "KOI8" was used for them due to socialism camp traditions. They doesnʼt fit into requirements listed above for cyrillic KOI-8 encodings.
KOI8-R is the first IANA-standardized encoding in this group; it is defined in IETF RFC 1489. IANA alias: CSKOI8R. The only used for russian Internet in mid-1990s and widespread now (but less and less, in preference to cp1251 and Unicode). It is applicable for English and Russian languages. It doesnʼt applicable even for Ukrainian; KOI8-R developer, Andrey Chernov, wanted pseudographic characters instead of additional letters.
KOI8-R is also known as CP878 in OS/2 and as CP20866 in Windows, csKOI8R.
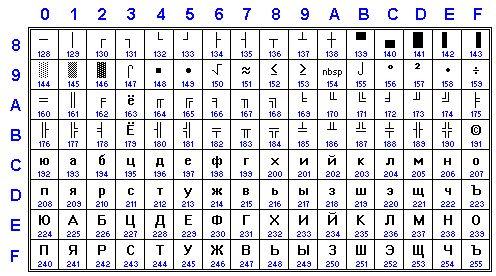
KOI8-U is modification of KOI8-R with inclusion of Ukrainian letters. First versions of KOI8-U had appeared in 1992, rather full localization package for Unix systems is known since 1994, but it wasnʼt tried to codify it for other world until 1997 after appearance of KOI8-RU draft (see below). Standard source is IETF RFC 2319. Now it is standard de facto for Ukrainian Internet.
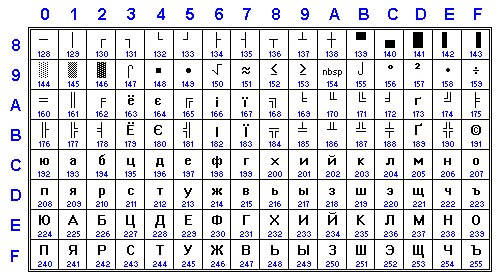
KOI8-RU was invented as private innovation of Yuri Demchenko from Kiev Politechnical Institute to provide KOI8-R-compatible encoding with letters of Slavonic exUSSR Cyrillic alphabets (Ukrainian, Belorussian), with positions borrowed from ISO-IR-111. In 1997 support of this encoding was added to Microsoft Outlook Express. This charset wasnʼt supported by Ukrainian Internet community due to presence of uncodified but used KOI8-U; the latter one was pushed instead to IETF. Not registered at IANA, but also supported by GNU iconv.
Microsoft defined CP21866 as KOI8-U but for a long time it really was KOI8-RU. In practice, there is too small difference between them as to be easily mixed.
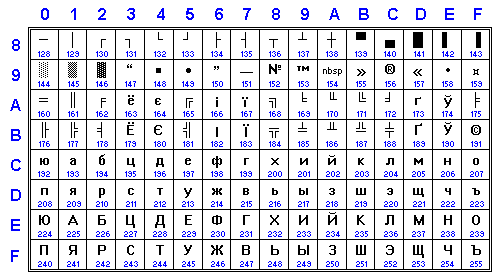
KOI8-F is innovation of Fingertipsoft which contains all letter of Russian, Ukrainian, Belorussian and Serbian alphabets. It isnʼt known to IANA or Windows, but is supported by newest Perl and used in some IRC networks because it covers letters from all Cyrillic charsets.

ISO-IR-111 (aliases: ECMA-Cyrillic, KOI8-E, ECMA-113:1986) is ECMA and ISO standardized cyrillic coding of KOI8 group. (Donʼt mix with ECMA-113:1988 which is effectively ISO-8859-5.) With KOI8-R compatibility in Russian letters, it defines many additional letters for Ukrainian, Belorussian and Serbian alphabets. But it doesnʼt contain ukrainian "ghe with upturn" and so has limited value for Ukrainian.
ISO-IR-111 has problem in IETF definitions: see ISO-IR-111 sore letter by Michael Sokolov. In a few words: while ISO/ECMA definition really has encoding of KOI8, RFC 1345 has erroneous definition of completely another encoding (identical to CP1251 in 0xC0-0xFF). This means high probabillity of implementations which erroneously use another encoding named as ISO-IR-111 or ECMA-Cyrillic.

PC adaptation of Soviet standard GOST 19768-87 defined new encodings: "main" ("osnovnaya") and "alternative" ("alternativnaya") in order to provide compatibility for new generation of computers based on IBM PC clones. The main idea was that "main" encoding shall be used for home-grown programs, and "alternative" one shall be used for programs developed outside of USSR. Formally they were created in the following way:
"Main" encoding very quickly died because it was incompatible with huge flow of programs developed outside of (ex-)USSR, but ISO-8859-5 is based on it. "Alternative" encoding, on the other side, had given a bunch of encodings compatible with cp437 and so with IBM PC pseudographics. Most used now are cp866 and ruscii.
Picture for "main" encoding of Soviet IBM PCʼs clones. This picture is somewhat broken because it shows Io/io in 0xF0/0xF1. This differs from original encoding which had there the same symbols there as in cp437, ≡(U+2261) and ±(U+00B1).
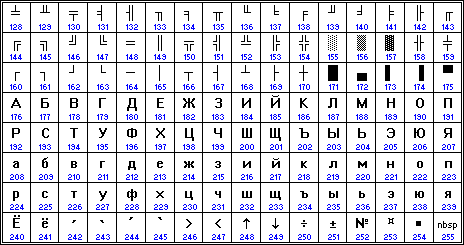
Picture for "alternative" encoding of Soviet IBM PCʼs clones. This picture is somewhat broken because it shows Io/io in 0xF0/0xF1. This differs from original encoding which had there the same symbols there as in cp437, ≡(U+2261) and ±(U+00B1).
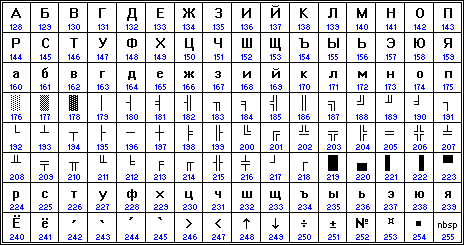
CP866 is Microsoftʼs invention based on PC clonesʼ "alternative" coding. It has some extensions after 0xF2 - Ukrainian Ji/ji, Ukrainian Ie/ie and Belorussian short U/u. It hasnʼt got Ukrainian "ghe with upturn" which wasnʼt officially restored yet at the moment, and Ukrainian/Belorussian I/i which was supposed to be unnesessary when having Latin I/i.
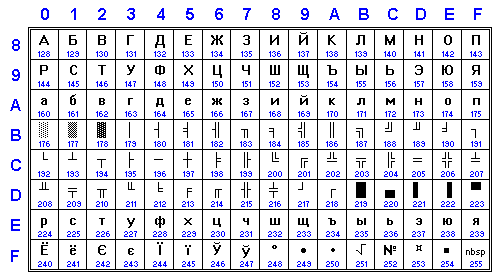
RUSCII (a.k.a. IBM CP1125, a.k.a. x-cp866-u in UUPC/Ache) is Ukrainian government standard (RST 2018-91) for DOS, based on common "alternative" encoding, but different from cp866 in 0xF2-0xF9. FreeBSD also has console fonts for it (cp866u-*) and map file (koi8-u2cp866u). It is known by GNU iconv as CP1125.
It seems this coding is also known as CP866NAV in TeX and Emacs, CP866NAV/IBM866NAV/866NAV in new GNU iconv. It is incompatible with CP866 in definition of Ukrainian letters, this caused some mess between encodings.
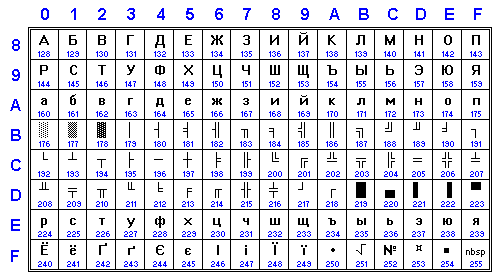
ISO-8859-5 is the ISO standard for cyrillic charset. Symbol range 0xB0-0xEF is the same as in "GOST main" encoding (see ALT group), due to its history. Ranges 0xA0-0xAF and 0xF0-0xFF contains many symbols of different Cyrillic alphabets including Ukrainian, Belorussian and Serbian. Same as in for ISO-IR-111, it doesnʼt contain Ukrainian "ghe with upturn".
Its usage in Internet and in other practice is very limited; really, it only was source of pain because no really widespread systems and system classes used it (used Alt, KOI8-*, cp1251 instead). The only class of systems for it known to me is big DBMS (DB/2, Oracle) but administrators systematically patched them to support more traditional codings. Using modern jargon, ISO-8859-5 is "epic fail". On the other side, the Cyrillic section of Unicode copies its main part (0xA0-0xFF) to U+0400...U+044F with minor changes.
IANA alias: Cyrillic. See also dramatic history for ECMA/ISO charset mutation. I have said it already: GOST 19768-87 had defined totally another encoding that was in previous GOST 19768-74. Donʼt ever mix them.
Aliases: ISO-IR-144, ISO_8859-5, ISO_8859-5:1988.
IBM name: CP915.
Windows name: CP28595.
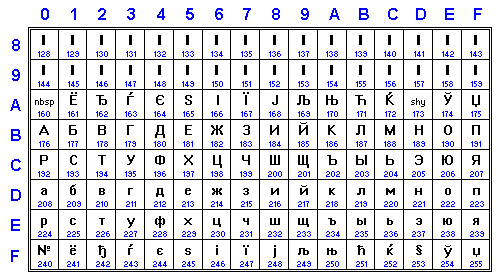
ISO-IR-153 is "restricted" variant of ISO-8859-5: it defines only 0xB0-0xEF, 0xA1 (Io) and 0xF1 (io). Often it is erroneously named as GOST_19768-74.
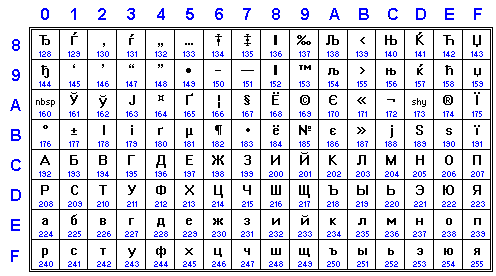
CP1251 was invented by Microsoft and ParaGraph (Moscow) as Cyrillic coding for Windows. A legend says that it was initially invented as a result of conversion cp437 -> iso-8859-1 applied to an early version of CP866 encoding, to simplify conversion process for DOS documents which encoding canʼt be determined. It contains most additional symbols for Ukrainian, Belorussian, and Serbian alphabets. Now it is one of the most popular encodings for Russian and Ukrainian, and the most popular one for Belorussian and Bulgarian, among 8-bit codings, used de facto in some areas (e.g. ICQ IM network, video subtitles...)
IANA name: windows-1251
Other links for this problem:
© 2001-2017 text by Valentin Nechayev
This page may be fully or partially cited with providing link to original place, and linked without any limitations. Also one can reuse it, except pictures, under GNU Free Documentation License or Creative Commons License.